1. tibero6 설치 파일 준비, license 발급


아래 공식 사이트에서 테스트용으로 무료 라이센스를 제공 (데모라이선스 신청)
https://technet.tmax.co.kr/ko/front/main/main.do
Technet
효율적인 시스템 관리를 위한 기술 전문 포탈, 테크넷서비스
technet.tmax.co.kr
2. JDK설치
Tibero를 설치하기 위해 JDK 1.5.17 이상 버전이 필요하다.
su - 명령어를 통해 root 계정으로 전환
yum install -y java-1.8.0-openjdk-devel.x86_64

JDK 설치하는 이유 : Tibero RDBMS서버는 java의존성이 없다. RDBMS(관계형 데이터베이스)서비스만 제공하는
호스트에는 굳이 설치하지 않아도 됨.
* tbexport, tbimport 등 java를 이용하는 client 유틸리티를 사용하기 위해서 설치하는 것으로 선택사항이다.
3. 패키지 설치

tibero 설치 시 필요한 패키지들을 설치
호스트네임이란 ? 네트워크에 연결된 장치들에게 부여되는 고유한 이름
hostnamectl set-hostname tibero
yum install -y gcc gcc-c++ libstdc++ libstdc++-devele compat-libstdc++ libaio libaio-devel
*rpm : 비인터넷 환경
rpm -ivh
* yum : 인터넷 환경에서 rpm패키지 설치(redhat package manager), 자동으로 필요한 패키지들을 설치해줌
* 비인터넷 환경에서 설치하려면 rpm을 다운받아서 설치
IP 고정
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="static"
IPADDR=192.168.86.128
NETMASK=255.255.255.0
GATEWAY=192.168.86.2
DNS1=8.8.8.8
*DNS1:문자주소를 ip주소로 번역해주는 역할
* 재시작하여 적용
service network restart
4. 커널 파라미터 설정
vi /etc/sysctl.conf
들어가서 i 누르면 입력 가능
getconf PAGE_SIZE
kernel.shmmni = 4096
kernel.shmall = 393216
kernel.shmmax = 1610612736
kernel.sem = 10000 32000 10000 10000
fs.file-max = 6815744
net.ipv4.ip_local_port_range = 1024 65500
shmmni = 전체 linux 시스템의 세마포어 셋의 최대 개수 (디폴트 값 = 4096)
shmall = 특정 시점에 시스템에서 사용 가능한 공유 메모리의 최대 크기 ceil(shmmax/PAGE_SIZE)
shmmax = OS 메모리 3GB일 때 계산법 : 1024*1024*1024*1.5(메모리 절반)을 계산하여 값을 입력. (byte)
공유 메모리 세그먼트의 최대 크기
sem = 세마포어 값 설정 (세마포어 수, 최대 개수, 연산 최대 수, 최대 값)
file-max = 리눅스에서 한번에 운용할 수 있는 파일 수
ip_local_port_range = 할당할 수 있는 포트 번호의 범위

세마포어(Semaphore)란?
공유된 자원에 여러개의 프로세스가 동시에 접근하면 문제가 발생함
이를 하나의 데이터에 하나의 프로세스만 접근할 수 있도록 제한해줌
제일 하단에 커널값 지정해준 후 esc :wq! 엔터로 저장하고 나오기
sysctl -p
Shell Limits설정
vi /etc/security/limits.conf
tibero soft nofile 1024
tibero hard nofile 65536
tibero soft nproc 2047
tibero hard nproc 16384
*soft : 새로운 프로그램을 생성하면 기본으로 적용되는 한도
*hard : 최대로 늘릴 수 있는 한도
*nproc (number of processes) : 프로세스 최대 개수
*nofile (number of open files) : 파일 열기 최대 개수
*nofile : MAX_SESSION_CNT / WTHR_PROC_CNT 이상으로 설정
*nproc : MAX_SESSION_CNT + 10000 이상으로 설정
selinux설정 (리눅스 커널 보안 모듈)
vi /etc/selinux/config
SELINUX=disabled
5. tibero설치 파일, license 업로드

여기서부터는 위와 같이 Xshell로 넘어와서 ctrl alt f

이렇게 왼쪽 로컬에서 오른쪽 tibero 가상 서버로 파일을 선택 후 드래그앤드롭하여
파일 업로드를 손쉽게 진행 할 수 있음

tar -xvf tibero6-bin-FS07_CS_2005-linux64-199301-opt.tar.gz
이제 불러온 tibero파일의 압축을 풀어준다
tip!
tar -x : tar 파일 압축 해제
tar -v : 명령에 대한 파일의 정보를 보여줌
tar -f : tar파일의 이름 지정

위처럼 tibero6폴더 생성이 됨

구조는 이렇게 생성된다
이제 tibero6 하위폴더인 license폴더에 우리가 발급받은 라이센스를 넣어주면 됨
(위에서 했던 것처럼 드래그앤드롭)
tip!

이건 리눅스서버에서 파일 위치 옮기는 법
mv 현재위치의옮길파일 옮길경로
scp 명령어로 로컬에서 서버로 파일 보내는 방법
파일위치 >scp 파일명 유저명@ip주소:/home/tibero

폴더는 -r 옵션 붙여서 보내면 된다.
6. 환경변수 설정
* export : 환경변수를 설정하고, 현재 셸 세션과 그 하위 프로세스에게 해당 변수를 전달하는 명령어
* bash_profile 란? 환경변수와 bash가 수행될 때 실행되는 프로그램을 제어하는 지역적인 시스템설정과 관련
-> 이 환경변수들은 오직 그 사용자에게만 한정되고 다른 사람에게는 영향을 미치지 않는다.
vi ./.bash_profile
위의 명령어로 환경변수 설정할 파일로 이동

i 누르고 아래 내용 삽입
export TB_HOME=/home/tibero/tibero6
export TB_SID=tibero
export LD_LIBRARY_PATH=$TB_HOME/lib:$TB_HOME/client/lib
export PATH=$PATH:$TB_HOME/bin:$TB_HOME/client/bin
TB_HOME = 티베로 엔진 설치 위치
TB_SID = 사용할 DB명 (데이터베이스 식별자), tibero인스턴스 이름
LD_LIBRARY_PATH = 응용 프로그램 구동에 필요한 라이브러리 경로
PATH = tibero 실행 파일을 찾을 경로
삽입 후 esc :wq!로 저장하고 나오기
source ./.bash_profile
위 명령어로 수정한 환경변수 적용!
7. tibero 환경파일 생성
datafile 디렉토리 생성 후
mkdir tbdata
sh $TB_HOME/config/gen_tip.sh
위에서 설정해준 $TB_HOME의 하위 폴더인 config에서

gen_tip.sh를 위처럼 실행하면 티베로 환경파일 생성!
※ ./gen_tip.sh ? DB생성 전에 nomount 단계를 거쳐야 하는데, 이 때 .tip파일을 읽어서 컨트롤 파일을 찾는다.

$TB_SID.tip 파일 설정

archive모드라면?

아카이브로그 파일 경로 정보도 tip파일에 넣어줘야한다.
tbdsn.tbr파일이란 ? 클라이언트가 티베로 데이터베이스에 접속하기 위한 필요한 정보를 가지는 파일
vi $TB_HOME/client/config/tbdsn.tbr
위 명령어로 해당 파일에 들어가서 수정해준다.

HOST=ip주소나 hostname을 적어줘도 된다. 다만 보안 상 hostname을 적어주는게 일반적이다.
PORT=리스너포트번호
DB_NAME=생성할 데이터베이스 이름
8. tibero DB 생성
tbboot nomount
아직 생성한 DB가 없기 때문에 프로세스만 기동하는 nomount모드로 실행하는 명령어
( ERROR!

해당 오류는 라이센스 발급 시 입력했던 hostname이 맞지 않다는 것
[리눅스 cent OS 7] root계정으로 전환하기 hostname변경 명령어
root 계정으로 전환하기 su - 입력 후 비밀번호 입력하기(비밀번호는 입력하더라도 화면에 표시 X) hostname 변경하기 해당 명령어 입력 후 엔터치면 기본 값으로 localhost.localdomain 또는 지정한 hostname
ittt.tistory.com
)
tbsql sys/tibero
tibero의 어드민 계정 == sys계정을 통해 로그인 (이때 /tibero는 sys계정의 default 비밀번호이다.)
※ sys계정 ? 최고 권한을 갖는 관리자 계정

위처럼 로그인을 하면 쿼리문을 적을 수 있게 나옴
create database "tibero"
user sys identified by tibero
maxinstances 8
maxdatafiles 100
character set UTF8
national character set UTF8
logfile
group 1 'log011.log' size 100M,
group 2 'log021.log' size 100M,
group 3 'log031.log' size 100M
maxloggroups 255
maxlogmembers 8
noarchivelog
datafile 'system001.dtf' size 100M autoextend on next 100M maxsize unlimited
default temporary tablespace TEMP
tempfile 'temp001.dtf' size 100M autoextend on next 100M maxsize unlimited
extent management local autoallocate
undo tablespace UNDO
datafile 'undo001.dtf' size 100M autoextend on next 100M maxsize unlimited
extent management local autoallocate;
tibero라는 데이터베이스 생성
해석
create database "tibero" : 티베로 라는 이름의 데이터 베이스 생성
user sys identified by tibero : 데이터 베이스에 접근할 수 있는 sys 계정 생성 및 비밀번호 설정
maxinstances 8 : 최대 8개의 인스턴스를 허용
maxdatafiles 100 : 최대 100개의 데이터 파일을 허용
character set UTF8 : 데이터베이스의 캐릭터 셋을 UTF-8 로 설정
national character set UTF8 : 국가 캐릭터 셋을 UTF-8 로 설정
logfile
group 1 'log001.log' size 100M,
group 2 'log002.log' size 100M,
group 3 'log003.log' size 100M : 3개의 로그 그룹을 생성하고 각각 100MB 크기의 로그 파일을 할당
maxloggroups 255 : 최대 255개의 로그 그룹 허용
maxlogmembers 8 : 최대 8개의 로그 멤버 허용
noarchivelog :아카이브로그 모드를 사용하지 않겠다는 뜻
datafile 'system001.dtf' size 100M autoextend on next 100M maxsize unlimited
: 'system001.dtf' 이라는 이름의 데이터 파일 생성 및 100MB크기로 초기화하며,
100MB 단위로 자동확장. 최대 크기는무제한 (반대 : autoextend off)
default temporary tablespace TEMP : TEMP라는 이름의 기본 임시 테이블 스페이스 생성
tempfile 'temp001.dtf' size 100M autoextend on next 100M maxsize unlimited
: 'temp001.dtf' 이라는 이름의 데이터 파일 생성 및 100MB크기로 초기화하며,
100MB 단위로 자동확장. 최대 크기는무제한
extent management local autoallocate : 로컬 오토 얼로케이트 확장 관리 사용
undo tablespace UNDO : UNDO라는 이름의 롤백(undo)테이블 스페이스 생성
datafile 'undo001.dtf' size 100M autoextend on next 100M maxsize unlimited
extent management local autoallocate;
quit
나가는 명령어

정상적으로 기동하기(데이터베이스 생성이 완료되면, 자동적으로 다운되기 때문에 tbdown 없이 바로 기동 가능)
9. Tibero Default 스키마 설치
※ 데이터베이스 스키마란 ? 관계형 데이터베이스에서 데이터가 구조화되는 방식을 정의함
sh $TB_HOME/scripts/system.sh


SYS 패스워드 : tibero
SYSCAT 패스워드 : syscat
입력 후 모든 과정에서 y를 눌러주면 설치 완료!
10. Tibero 확인
ps -ef | grep tbsvr
여기서 -ef는 두 가지 옵션의 결합이다.
- -e 옵션:
- -e는 모든 프로세스(ps)를 나열. 시스템 전체의 모든 프로세스를 표시하며, 현재 사용자와 관계없이 모든 프로세스(ps)를 보여줌.
- -f 옵션:
- -f는 확장된 형식(extended format)으로 출력함. 이 옵션을 사용하면 프로세스(ps)에 대한 자세한 정보가 표시됨.
따라서 ps -ef 명령은 시스템 전체의 모든 프로세스에 대한 확장된 형식의 정보를 나열.
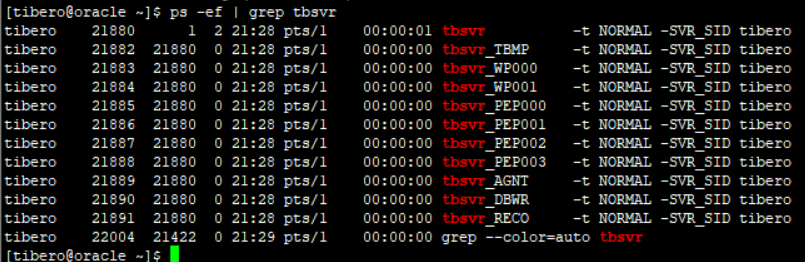
- tbsvr : Tibero를 구성하는실행 파일
- TBMP(Tibero Manager) : sys유저로 접속해서 DB를 관리할 때 작업 프로세스(쓰레드)들이 들어있고,
이를 통해 관리자가 관리는 위한 SQL등을 사용한다. 관리자도 평상시에는
서비스 포트를 사용하지만 다 소진이 되면(session full) 매니저 프로세스에 있는
스페셜 포트로 접속을 하게 된다.
- WP(work process) : 사용자 세션 처리, sql문을 실행하는 주요 작업 프로세스
컨트롤 쓰레드 : 워커 프로세스마다 하나씩 만들어짐. 티베로가 기동될 때 초기화
파라미터에 설정된 수만큼 생성. 클라이언트의 새로운 접속 요청이 오면 현재 작업
대기중인 워커 쓰레드에 클라이언트의 접속을 할당.
워커 쓰레드 : 사용자와 1:1로 통신하며, 클라이언트가 보내는 메세지를 받아
처리하고 그 결과를 돌려줌.
주로 sql 파싱이나 최적화 수행 등의 데이터베이스 시스템이 수행하는
작업 대부분이 워커 프로세스에서 일어남.
* 워커 쓰레드는 하나의 사용자와 접속하게 되므로 티베로에 동시 접속이 가능한 사용자 세션 수는 WTHR_PROC_CNT * _WTHR_PER_PROC = MAX_SESSION_COUNT가 됨.
* 백그라운드는 사용자의 접속 요청을 직접 받지않고, 워커쓰레드나 다른 백그라운드 프로세스가
요청하는 경우 그리고 일정한 주기에 따라 동작하는 작업 시간이 오래 걸리는 디스크 작업을 수행하는
독립된 프로세스이다.
- PEP(Parallel Execution Performance) : SQL을 처리할 때에 locality를 극대화하기 위해서
WTHR(워킹 스레드)들을 하나의 PEP에서 할당
- AGNT (agent process): 시스템 유지를 위해 주기적으로 처리해야 하는 티베로 내부의 작업을 담당.
티베로에서 중앙처리장치(CPU)의 작업을 필요로 할 경우 실행 순서를
스케줄링하는 디스패처 역할, 인스턴스를 복구하거나 프로세스를 관리하는 시스템
모니터링 역할, 서로 공유되는 객체간의 동기화를 설정하는 리시버역할,
락과 관련된 처리를 하는 역할, 시퀀스값을 생성, 처리하는 역할 등의
다양한 것들이 있다.
- DBWR : 데이터 베이스에서 변경된 내용을 디스크에 기록하는 일과 연관된 스레드들이 모여 있는 프로세스.
사용자가 변경한 블록을 디스크에 주기적으로 기록하는 스레드
Redo Log를 DISK에 기록하는 스레드
두 스레드를 통해 데이터베이스의 체크포인트 과정을 관할하는 체크포인트 스레드
- RECO: 복구 전용 프로세스.
티베로가 비정상적으로 종료되어 크래쉬 복구가 필요한 경우에는 자체적으로 수행.
티베로 6 이전 버전에서는 첫번째 워커 프로세스가 담당했지만 6부터는 복구 프로세스를 마련.
tbsql sys/tibero
데이터베이스 이름 확인
SELECT name FROM v$database;
인스턴스 확인
select status from v$instance
*tbinary를 활용하여 점검
cd tbinary/tbchk
sh tbchk.sh
- MGWP (manager worker process) : 시스템 관리 용도 프로세스.
관리자의 접속 요청을 받아 이를 시스템 관리 용도로 예약된
워커 스레드에 접속을 할당.
기본적으로 워커 프로세스와 동일한 역할을 수행하지만 리스너를
거치지 않고, 스페셜 포트를 통해 직접 접속.
sys계정만 접속 허용. Local에서만 접속 가능.
- FGWP (Foreground Process == Worker Process) : 클라이언트 프로세스와 직접 통신하며,
사용자의 요청을 처리하는 역할
- PEWP (Parallel Execution Worker Process) : 한 개의 작업을 여러 개로 나누어 동시 처리를 실행.
데이터 웨어하우스(DW: Data Warehouse)와
BI(Business Information)를 지원하는
대용량 DB에서 발생하는 데이터 처리의
응답 시간을 획기적으로 줄일 수 있다.
'DB > Tibero' 카테고리의 다른 글
| [Tibero 6] tbinary/monitor 활용 방법 tibero alias 모음 (3) | 2024.01.17 |
|---|---|
| [Tibero 6] Tibero Database 점검하는 방법 점검 사항 (0) | 2024.01.17 |
| [Linux] 리눅스 cent OS 7에서 Tibero 6 패치 (Fix Set) (1) | 2024.01.16 |
| [Tibero6 Error] 티베로 오류 A shared memory segment with the same key already exists (0) | 2024.01.16 |
| [Tibero] 티베로 개념 구조 (0) | 2024.01.10 |



